НАУЧНОЕ ОБОСНОВАНИЕ НЕОБХОДИМОСТИ И ФОРМИРОВАНИЕ ТРЕБОВАНИЙ К АВТОМАТИЗИРОВАННОЙ ИНФОРМАЦИОННОЙ СИСТЕМЕ УПРАВЛЕНИЯ БЕЗОПАСНОСТЬЮ ПОЛЕТОВ
Содержание:
- Автоматизация процессов сбора и хранения данных по безопасности полетов как насущная потребность времени
- Основные характеристики автоматизированной информационной системы безопасности полетов. Базовый функционал
- Поиск информации
- Индексирование документов
- Рубрикация данных
- Характеристика расширенного функционала автоматизированной информационной системы безопасности полетов
- Обработка естественно-языковых текстов
- Автоматическая классификация документов
- Машинное аннотирование
- Автоматизированное извлечение знаний
- Идентификация информационных объектов
- Извлечение знаний
- Мониторинг фактографической информации
- Автоматизированное ведение досье на объект
- Мониторинг ситуаций в соответствии с их типологиями
- Литература
Обозначены проблемы информационного обеспечения процедур оценивания и управления уровнем безопасности полетов. Обоснована необходимость автоматизации сбора, хранения, представления и использования информации о состоянии авиационно-транспортной системы на всех уровнях и этапах управления безопасностью полетов. Сформированы требования к автоматизированной информационной системе безопасности полетов (АИСБП) и основные характеристики АИСБП. Приведено описание основных технологических процессов базового и расширенного функционалов перспективной АИСБП.
Ключевые слова: автоматизированная информационная система управления безопасностью полетов.
Автоматизация процессов сбора и хранения данных по безопасности полетов как насущная потребность времени
Управление безопасностью полетов (БП) на международном, государственном, отраслевом, ведомственном или корпоративном уровнях неизбежно связано со сбором, обработкой, накоплением (хранением), анализом и представлением информации о предшествующем, текущем и предстоящем состояниях авиационно-транспортной системы (АТС), поскольку управляемым может быть только то, что измеряемо. При реализации ретроактивной, проактивной стратегии управления БП [1] или активной стратегии превентивного управления [2] обязательными этапами управления БП являются:
1. Сбор данных (наличие системы сбора и обработки данных с механизмом обмена информацией).
2. Анализ данных.
3. Приоритезация деятельности по результатам анализа данных (на основании факторного и/или многофакторного анализа информации об авиационных событиях).
4. Выработка рекомендаций по управляющим (корректирующим) действиям.
5. «Обратная связь» (т.е. повторное оценивание состояния БП - априорное и/или апостериорное - с оцениванием эффективности планируемых и/или выполненных управляющих воздействий).
Уже на первом этапе управления БП обозначается двоякая информационная проблема. С одной стороны, это - дефицит информации об авиационных происшествиях (АП), как об исключительно редких событиях, в результате которых восстановление информации - отдельная проблема. С другой стороны, при оценивании БП, как состояния АТС любого уровня, предполагается использование информации, позволяющей оценивать динамику текущего состояния АТС косвенно, по динамике характеристик и параметров, определяющих состояние не обязательно всей АТС, а преимущественно - ее компонентов, связей и действующих возмущений [3]. В отличие от АП в данном случае оцениванию подлежит информация обо всей летной деятельности, включая полеты, выполненные в штатном режиме, количество которых растет в процессе эксплуатации.
Отсюда очевидна необходимость разработки и внедрения баз данных (БД), обеспечивающих управление БП на всех уровнях.
Технические требования к БД формируются с учетом обеспечиваемых процедур в управлении БП (надзор за БП, контроль за показателями БП, оценивание состояния АТС с позиций наличия (или отсутствия) факторов риска и факторов предотвращения АП, их количественных оценок и др.). Поэтому структура БД и процедуры управления ею должны определяться уровнем пользования: международный, государственный, ведомственный, корпоративный.
На международном уровне основой математического обеспечения ИКАО является разработка, используемая Европейским координационным центром системы представления данных об АП (ECCAIRS). Обеспечивается полное соответствие форматов сообщений Евросоюза и ИКАО и их взаимодействие. Использована методика обработки данных и составления сообщений по модифицированной Системе предоставления данных об авиационных происшествиях/инцидентах ADREP - 2000. Разработка функционально сосредоточена на вводе и запоминании несистемной информации, создании устройств преобразования данных предшествовавшей системы ADREP и данных, получаемых из баз данных государств-участников Соглашения. Разработаны меры по обеспечению конфиденциальности информации о БП [4, 5]. Система ECCAIRS обеспечивает выполнение совместного анализа информации библиотек сообщений по БП различных пользователей. Библиотека постоянно обновляется и доступна для пользователей. Международный обмен данными об АП/инцидентах обеспечивает широкую возможность для ознакомления с опытом, лежащим в основе разработки документов по обеспечению БП. Для достижения максимальной эффективности необходимо, чтобы основные методы кодирования информации были совместимы с другими системами представления данных (государственными или ведомственными), особенно это важно для систем электронной обработки данных (EDP) [6, 7].
В соответствии с положениями Приложения 13 к Конвенции о международной гражданской авиации [8] государства-члены Сообщества представляют ИКАО информацию обо всех АП, затрагивающих воздушные суда (ВС) с максимальной сертифицированной массой более 2250 кг и о тех авиационных инцидентах с ВС массой более 5700 кг, которые имеют важное значение для обеспечения БП и предотвращения АП.
Согласно требованиям ИКАО 2006 г. [1] «Система сбора и обработки данных о безопасности полетов» охватывает системы обработки и представления данных, базы данных, механизмы обмена информацией и регистрируемую информацию, а также включают дополнительные данные, полученные с помощью расследований АП и инцидентов, систем обязательного представления данных об инцидентах, систем добровольного представления данных об инцидентах и систем представления отслеживаемых данных (включая автоматизированные и неавтоматизированные системы сбора данных). Системы представления данных о БП не должны ограничиваться инцидентами, а должны предусматривать представление сведений об опасных факторах, т.е. о небезопасных условиях, которые еще не привели к инциденту (о факторах риска АП).
Кроме того, в рамках ИКАО внедрены и ведутся специализированные базы данных, в том числе: базы данных о столкновении с птицами (Руководство по системе информации ИКАО о столкновении с птицами (IBIS) (Doc 9332)), «банк» данных о технических характеристиках аэропортов (Справочник по двусторонним соглашениям о воздушных сообщениях (Doc 9511)) и др.
Глобальный план обеспечения БП ИКАО предусматривает создание и интеграцию в масштабах отрасли баз данных коллективного пользования об инцидентах/ошибках, демонстрацию и пропаганду преимуществ транспарентности в представлении данных (Глобальная инициатива БП № 6 «Эффективная система представления и анализа данных об ошибках и инцидентах в отрасли» п. 3) [9].
В США действует широкая система представления данных об АП и инцидентах, известная как «Система донесений о безопасности полетов» (ASRS) (http//asrs.ars.nasa.gov). Система ASRS функционирует независимо от Федерального авиационного управления (FAA) и управляется НАСА. Известны аналогичные системы: BASIS (авиакомпания «British Airways»), INDICATE (Идентификация необходимых средств защиты в гражданском воздушном транспорте, Австралия), AIRS (компания «Airbus Indastrie») и др.[1].
В отечественной гражданской авиации, начиная с 1976 года, автоматизация процессов обработки данных об АП, инцидентах («предпосылках к летному происшествию» - в прежней терминологии) и других классифицируемых событиях для решения вопросов информационного обеспечения центрального аппарата, организаций и предприятий авиационной отрасли сведениями о состоянии БП решались информационно-справочной системой АСУ «Безопасность» [10]. После многократного совершенствования Автоматизированная система обеспечения безопасности полетов воздушных судов гражданской авиации Российской Федерации (АСОБП) отражает требования и положения Воздушного кодекса РФ и Правил расследования авиационных происшествий и инцидентов с гражданскими воздушными судами в РФ [11] и обеспечивает информацией Министерство транспорта РФ, руководящий состав Росавиации и Ространснадзора, НИИ и учебные заведения гражданской авиации, территориальные органы воздушного транспорта Минтранса России [10].
В соответствии с Государственной программой обеспечения БП ВС гражданской авиации РФ Система программных мероприятий предусматривает координацию деятельности ведомств и организаций в интересах обеспечения БП ведением баз данных о свидетельствах авиационного персонала, об удостоверениях о летной годности воздушных судов и сертификатах организаций гражданской авиации, о нарушениях воздушного законодательства РФ и сведениях, касающихся АП (инцидентов) [12].
Помимо государственных систем представления данных об инцидентах авиакомпаниям, поставщикам обслуживания УВД и эксплуатантам аэропортов предписывается иметь «внутренние» системы представления данных об опасных факторах и инцидентах [1].
Корпоративные БД должны обеспечивать функционирование соответствующих систем управления БП, поэтому строить их следует в соответствии с выбранной или выработанной стратегией управления БП в авиакомпании. Особого подхода к корпоративной БД требует активное управление. Процедура оценивания и прогнозирования уровня БП [3] выполнима при наличии постоянно обновляемой информации о факторах риска и факторах предотвращения АП с результатами текущего количественного оценивания частоты (вероятности) и степени их влияния на безопасность предстоящих полетов.
Основные характеристики автоматизированной информационной системы безопасности полетов. Базовый функционал
Основные задачи, решаемые на основе создания БД по БП, направлены на информационное обеспечение процедур контроля за показателями БП (надзора), текущего и прогнозного оценивания состояния АТС и одновременно - на повышение уровня информированности специалистов в вопросах управления БП. Это такие задачи, как:
- регистрация авиационных событий, отдельных и совокупных факторов риска АП со структурированием их по ряду классификационных признаков;
- связь событий с источниками информации или документами (отчет, аналитический обзор, массив статистических данных и т.д.);
- отслеживание и выявление тенденций, обеспечение своевременного выявления проблем;
- подготовка анализа, схем, диаграмм, обеспечение наглядности представления данных о БП за счет консолидации данных из различных источников;
- сверка архивной информации;
- обмен данными (информацией с другими источниками);
- сигнализация об истечении сроков принятия мер;
- обеспечение непосредственного доступа руководителя к актуальным данным о состоянии АТС;
- повышение эффективности работы специалистов по управлению БП;
- снижение затрат на формирование регламентированной отчетности.
Успешное решение перечисленных задач базируется на эффективном функционировании следующих технологических процессов перспективной информационной системы [13]:
- поиск информации;
- индексирование документов;
- рубрикация данных;
- обработка естественно-языковых текстов;
- автоматическая классификация документов;
- автоматическое извлечение данных;
- мониторинг фактографической информации.
Следует отметить, что первые три процесса относятся к так называемому базовому функционалу системы, а остальные – к расширенному.
На первом этапе необходимо обнаружить требуемую информацию в разнородных внешних источниках. Основные возможности поисковых машин:
- индексирование текстов и поиск по ключевым словам (по индексу);
- морфологический поиск - разбор и отождествление различных грамматических форм слов;
- логический язык запросов, позволяющий задавать условия на совместное вхождение ключевых слов в искомый документ;
- ранжирование по степени соответствия документа запросу.
«Классическая» поисковая машина умеет найти по запросу из нескольких слов все документы, в которые данные слова входят, и представить их пользователю.
Этой простой возможности при росте объемов текстовых баз становится совершенно недостаточно, и в последнее время поисковые машины начинают оснащаться средствами извлечения знаний. Необходимо поддерживать следующие виды поиска:
Итеративный поиск: функция «найти похожие». Позволяет постепенно уточнить запрос: указать на один или несколько найденных документов и найти аналогичные по содержанию документы. Выполняется поиск путем превращения документа в поисковый запрос с определенной степенью «сжатия»).
Поиск по выборке. Если по первому запросу поисковая машина нашла слишком много документов, то второй запрос с заданием дополнительных параметров проводится по найденной ранее выборке, тем самым уточняя поиск.
Запрос на естественном языке. Запрос на естественном языке позволяет пользователю просто задать поисковой машине вопрос в свободной форме, как если бы он задавался человеку. Реализуется данная функция путем отбрасывания шумовых слов и выражений (как, скажи, где, за), выделения грамматической структуры запроса, подстановки синонимов и т. п.
Тезаурусы. Тезаурусы (словари) служат для расширения запроса и включают синонимы, антонимы, родственные слова, «вышестоящие» и «нижестоящие» категории и понятия (военный-офицер-капитан).
Для эффективной организации поиска документов необходимо реализовать полнотекстовое индексирование с учетом морфологии и семантики языка (рис. 1). На основе результатов морфологического анализа текстов, слова преобразуются в словоформы с отсечением суффиксов и окончаний, что позволяет в дальнейшем искать склонения и спряжения шаблонов.
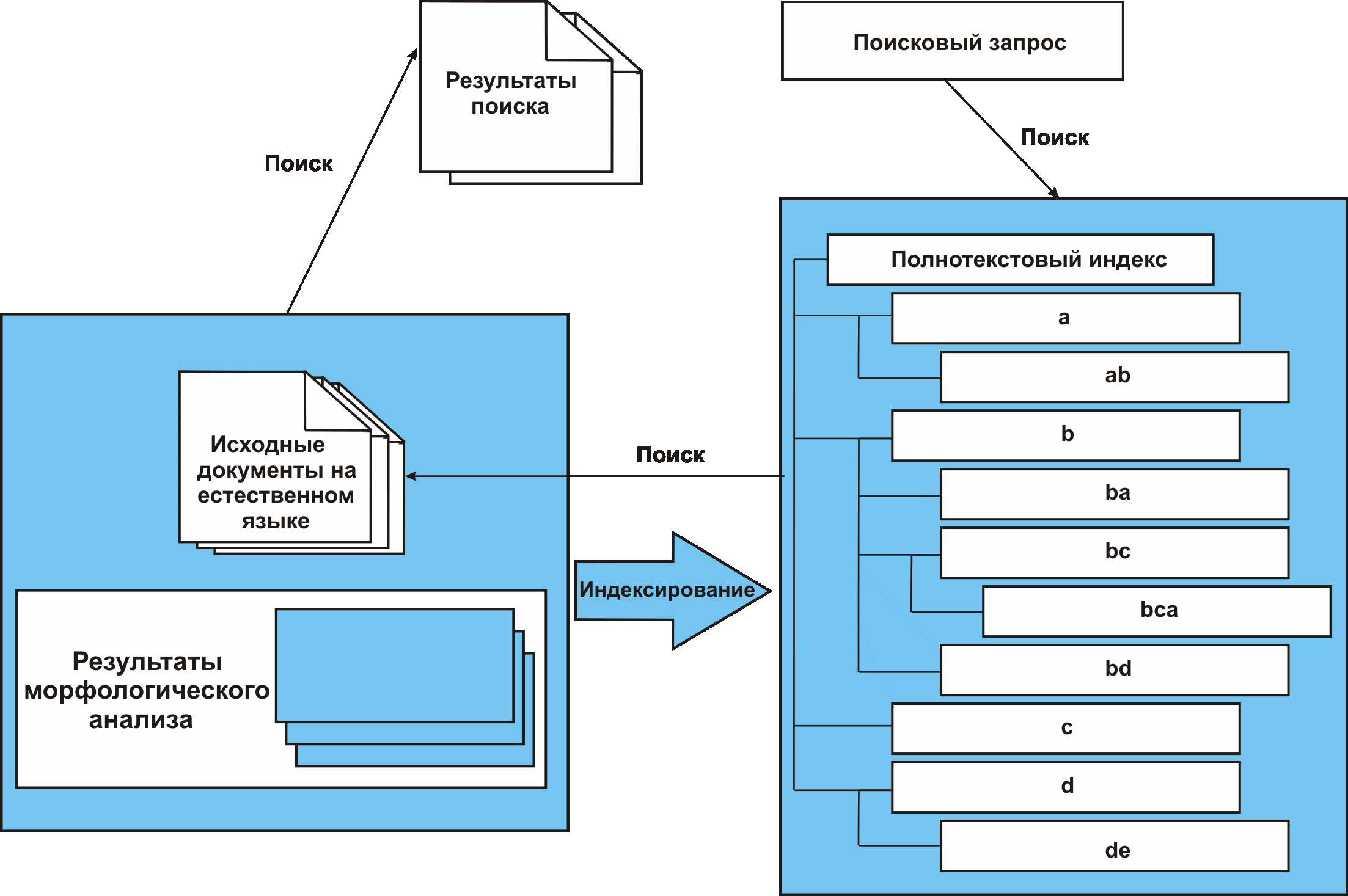
Увеличить guziy032009-01.gif (96кб)
Рис. 1. Общая схема индексирования
Каталоги (рубрикаторы или классификаторы) организуют множества документов в деревья или целые леса рубрик. Создатели классификаторов придумывают достаточно логичное и прозрачное дерево категорий, а затем наполняют его ссылками на документы и прочие ресурсы и составляют к ссылкам краткие аннотации.
Эта работа делается вручную, в частности потому, что отнесение документа к нужным рубрикам - процесс в высшей степени неформальный. Каталоги предоставляют более удобный вид доступа к данным, так как они больше, чем поисковые машины, похожи на знания за счет своей структурированности. Однако для эффективного использования каталога пользователю нужно еще угадать принцип структуризации, который был применен при его создании. Для компенсации неудобств каталогов (не все пользователи могут быть знакомы с логикой каталога), в последнее время в них стали включать средства поиска. Поисковые машины также стали снабжаться каталогами.
Схема рубрикации документов показана на рис. 2.
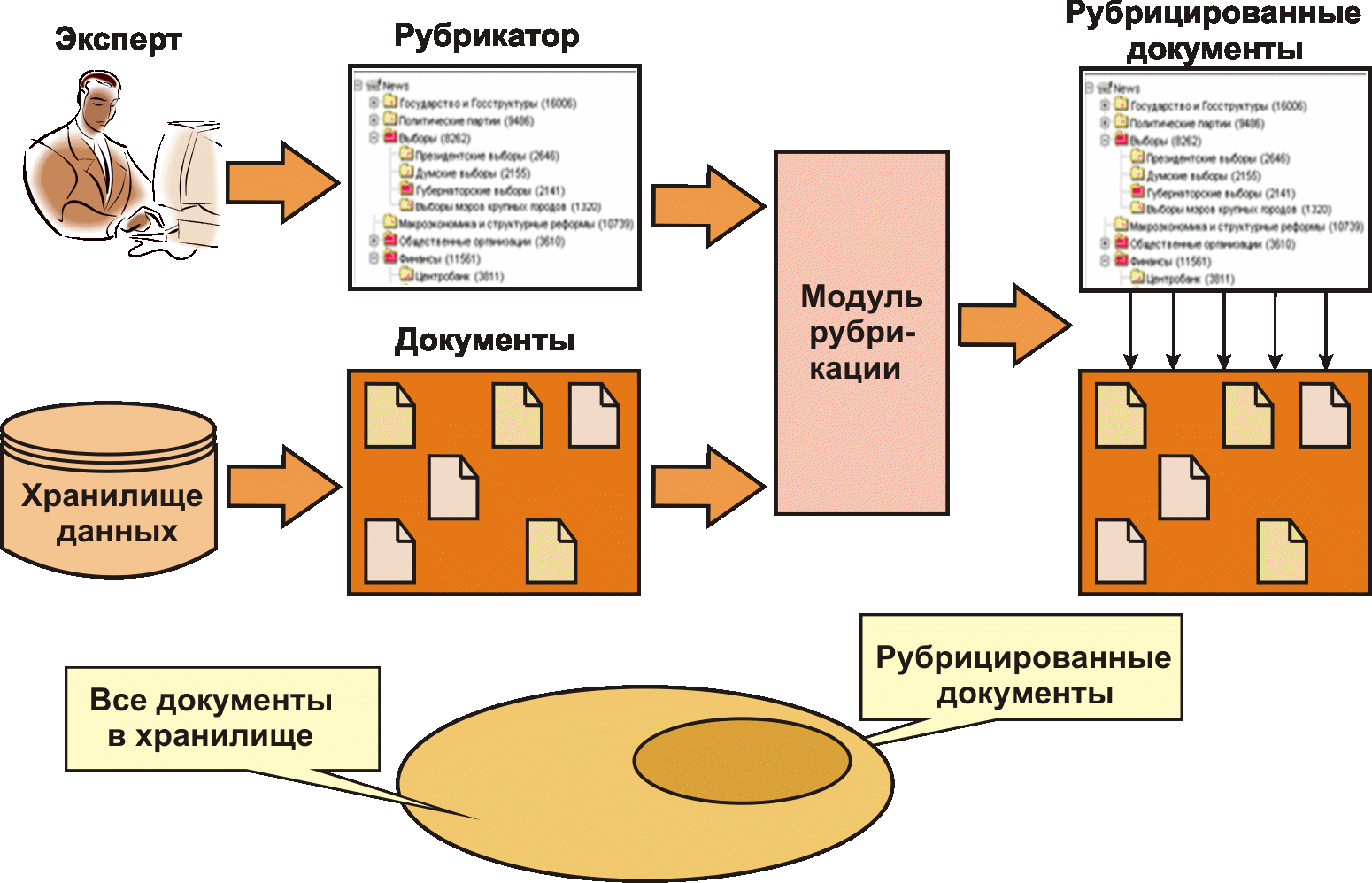
Увеличить guziy032009-02.gif (153кб)
Рис. 2. Рубрикация документов
Характеристика расширенного функционала автоматизированной информационной системы безопасности полетов
Создание перспективной информационной системы БП может носить эволюционный характер: после внедрения базового функционала можно приступать к реализации расширенного функционала.
Обработка естественно-языковых текстов
После получения интересующей информации из внешних источников для повышения эффективности восприятия ее необходимо обработать специальным образом.
На сегодняшний день системы обработки слабоструктурированной документальной информации являются неотъемлемым инструментом аналитических отделов организаций. В зависимости от решаемых задач, данные системы обычно разделяются на несколько классов: системы автоматической рубрикации и полнотекстового поиска, системы кластерного анализа и системы обработки фактографической информации. Несмотря на функциональные отличия систем разных классов, практически во всех них производится начальная обработка исходной документальной информации, представленной на естественном языке [14].
Обработка документальной информации осуществляется с использованием средств морфологического, синтаксического и семантического анализа. Кроме того, исходные тексты сообщений также сохраняются в хранилище данных. Морфологический анализ обеспечивает возможность индексирования и полнотекстового поиска документов, а также их кластеризации и рубрикации в соответствии с изначально задаваемыми рубриками.
Технологии семантического анализа текстов позволяют проводить автоматическое преобразование документальной информации в фактографическую и первичную обработку полученной фактографической информации (рис. 3).
В процессе первичной обработки фактографической информации осуществляется идентификация и слияние информационных объектов, устранение противоречивости информации и получение выводной информации в результате применения базовых правил ее логического преобразования.
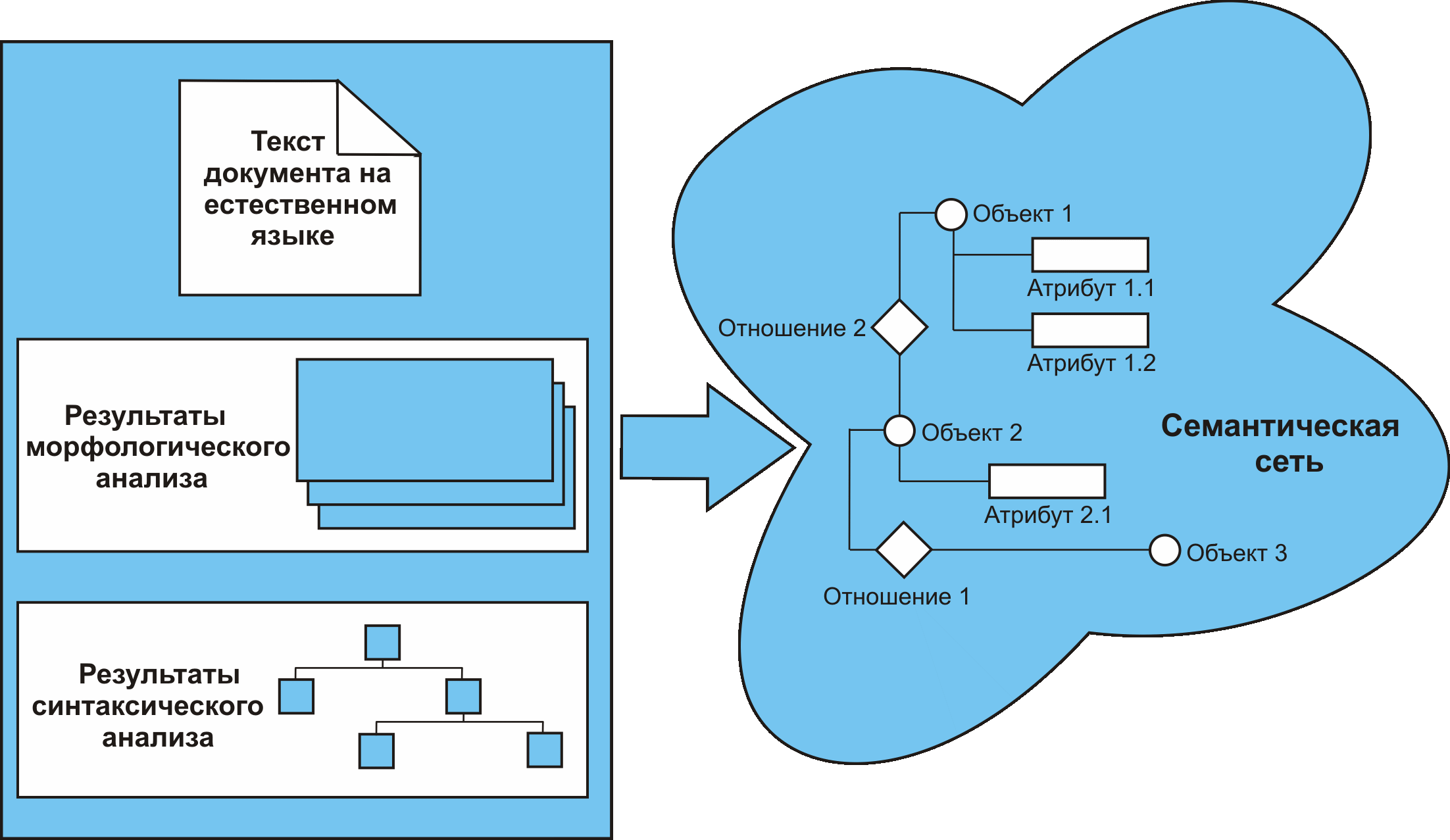
Увеличить guziy032009-03.gif (99кб)
Рис. 3. Общая схема логико-семантического анализа
Автоматическая классификация документов
Задачи классификации решаются на основе метода списка ключевых слов, метода поисковых запросов, метода «истинной» классификации.
Списки ключевых слов. Самый простой способ сортировать входной поток документов по нужным категориям (рубрикам) - задать для каждой рубрики набор ключевых слов, которые позволяют отнести документ к данной рубрике. Список ключевых слов служит в этом случае простым семантическим образом рубрики.
Как и многие другие простые способы, с реальными документами этот способ работает далеко не во всех случаях. Содержащиеся в программе или вносимые пользователем ключевые слова могут иметь в реальности синонимы, различные формы, могут быть действительно важными или не значить ничего именно в данном контексте. Кроме того, для языков с высокой изменчивостью слов - русского, немецкого и других - этот способ работает плохо.
Поисковые запросы как основа классификации. Более удачный способ - превратить списки ключевых слов для каждой рубрики в поисковый запрос, передать поисковой машине и применить его к множеству новых документов. Таким образом, можно получить более аккуратно ранжированный список документов, близких данной рубрике. Кроме того, можно подключить к классификации морфологические модули и словари синонимов.
Недостатки данного способа заключаются в том, что в описанном виде он также применим только для фиксированного набора рубрик и для созданного вручную множества ключевых слов.
«Истинная» автоматическая классификация. Существуют программы-классификаторы, которые избавляют пользователя от рутинной и сложной работы и составления семантических рубрик. Она реализуется путем указания программе рубрик и отнесенных к ним обучающих выборок документов. Программа выделяет в обучающих текстах значимые термины (слова и словосочетания), приводит их к словарным формам, составляет распределение терминов по рубрикам и документам, подсчитывает различительную силу каждого термина для данной рубрики и составляет семантические образы из наиболее различительных терминов.
В дальнейшем, при классификации входного потока, программа может использовать поисковые запросы или иным способом вычислять смысловую близость документа к рубрикам.
Классификация по таким семантическим образам работает гораздо лучше, чем по составленным человеком спискам ключевых слов.
В процессе работы системы системный администратор может время от времени обновлять ее - перестраивать семантические образы, применяя вновь полученные документы, чтобы уточнить их, благо делается это автоматически и быстро.
Существуют другие способы классификации документов, основанные на нейронных сетях, методах кластеризации, отображения документов в формальные многомерные пространства и т. д.
Схема процесса автоматической классификации показана на рис. 4.
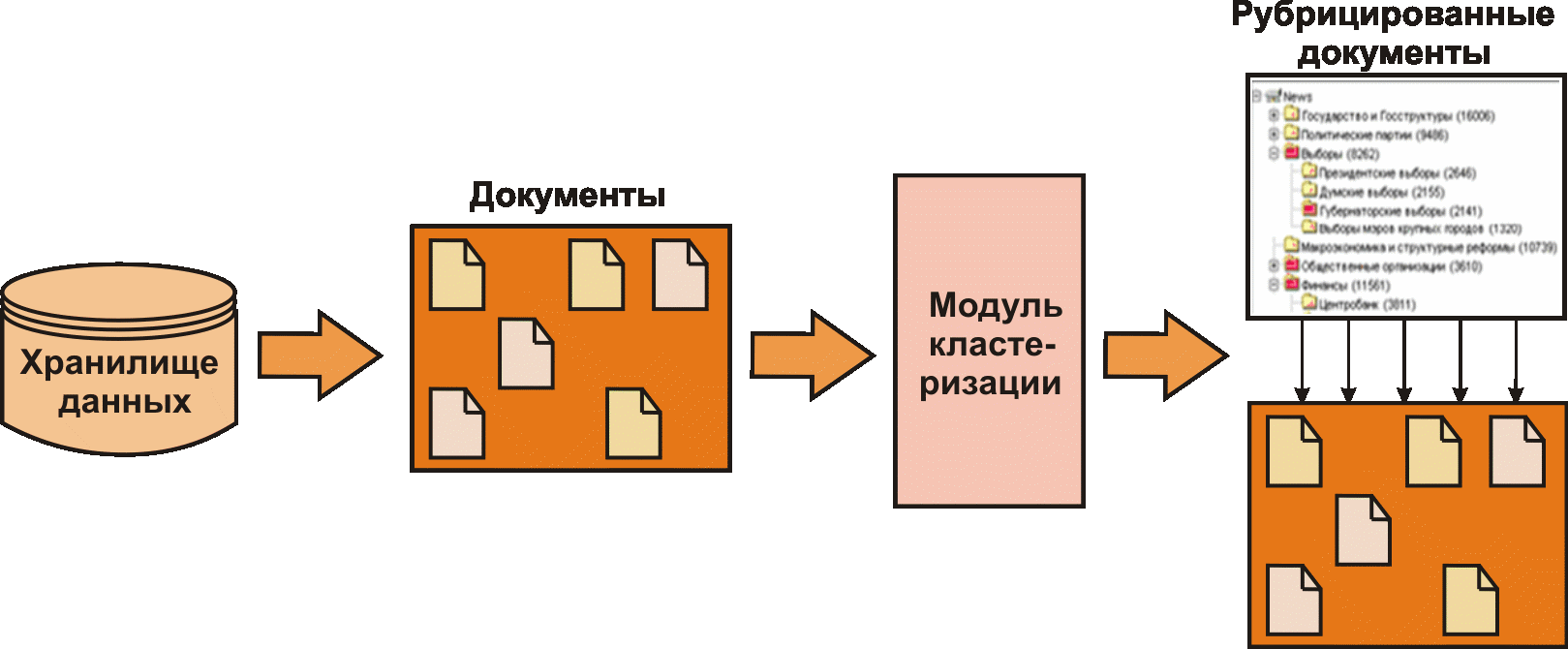
Увеличить guziy032009-04.gif (71кб)
Рис. 4. Авторубрикация (кластеризация) информации
Программа извлекает из текста те фрагменты, которые считает важными, и объединяет их в аннотацию. Важность конкретного предложения определяется по различным параметрам, в частности по так называемым маркерам важности, (например, «в заключение нужно сказать, что...»), количеству содержательных слов в нем и т. д.
В наиболее развитых средствах аннотирования учитывается также зависимость предложений друг от друга с тем, чтобы не вносить в аннотацию обрывки, начинающиеся, например, со слов «К тому же...», «В-третьих...» и т. п. Чтобы аннотация получилась связной, программа подбирает группы взаимосвязанных (взаимозависимых) предложений, а затем соединяет их, для большей связности немного изменяя на стыках.
Автоматизированное извлечение знаний
Процедура обработки информации на естественном языке, описанная выше, обычно является только первым этапом в общем процессе обработки документальной информации. Комплексным результатом первичной обработки является массив связанных фактографических данных, для которого предусмотрен ряд процедур последующей обработки, а именно [15]:
- идентификация информационных объектов;
- извлечение знаний;
- мониторинг фактографической информации.
Идентификация информационных объектов
Для выделенных на этапе первичной обработки из различных источников информационных объектов выполняется процедура идентификации, позволяющая выявить сходные информационные объекты, полученные из различных источников.
При идентификации объектов выделяются два основных типа связей - связи похожести и связи совпадения. Совпадающими считаются информационные объекты, имеющие одинаковые значения для определенного набора ключевых атрибутов. Для них может быть автоматически выполнена процедура слияния, которая объединит информационные объекты из различных источников. Связи похожести, как правило, обрабатываются специалистом-аналитиком (аналитик на основе экспертных знаний определяет, являются ли информационные объекты совпадающими, и выполняет, при необходимости, их ручное слияние) перед началом выполнения процедуры извлечения знаний.
Важной особенностью процедуры идентификации является возможность соотнесения вновь помещаемых в фактографическую базу информационных объектов с уже имеющимися. Это позволяет решать задачи мониторинга стандартных ситуаций.
После того как проведена идентификация и слияние совпадающих информационных объектов сформированный массив фактографической информации готов к извлечению из него знаний, с применением следующих процедур:
- контекстный анализ;
- ситуативный анализ;
- поиск цепочек связей;
- нечеткий поиск;
- полнотекстовый поиск похожих документов.
Контекстный анализ объектов - это поиск в массиве фактографической информации всех связей указанного объекта, а также всех объектов, связанных с исходным, с возможностью получения исходных документов, содержащих описания обнаруженных объектов.
Он позволяет аналитику выявить ключевые объекты анализа, скрытые и косвенные связи выбранного объекта или группы объектов.
Ситуативный анализ объектов - поиск в массиве фактографической информации связанных объектов, как для отдельных объектов, так и для их групп в соответствии с заданными ограничениями на глубину и характеристики поискового алгоритма.
Ситуативный анализ позволяет выявлять в массиве фактографической информации неявные закономерности, получая, таким образом, качественно новые знания.
Поиск цепочек связей позволяет аналитику обнаруживать прямые и опосредованные связи заданной глубины между объектами и группами объектов. Данный режим позволяет, в первую очередь, автоматически выполнять проверку экспертных предположений о том, что объекты имеют связь.
Окраски связей обеспечивают автоматический поиск связей требуемого вида. Например, у нас имеется связь между объектами вида «вхождение в один документ», а нас интересует, есть ли связь «наличие финансовых операций между объектами».
Нечеткий поиск документов позволяет задать сразу несколько критериев – по текстам документов, по рубрикам документов, по атрибутам документов и скомбинировать их в запрос любой степени сложности [16].
Полнотекстовый поиск похожих документов позволяет выполнять отбор в массиве фактографической информации фрагментов, аналогичных или похожих на описание ситуации на естественном языке, вводимое аналитиком (ограничения на характер и количество отличий выбираемых ситуаций от указанной также задается аналитиком). Из запроса выделяются все значимые слова и признаки. Они приводятся к единому виду и дополняются аналитическими характеристиками, порождаемыми самой системой и отражающими особенность ситуации. Далее осуществляется поиск похожих ситуаций с аналогичными признаками. Найденные документы упорядочиваются по степени сходства, которая определяется с учетом следующих факторов: количества и значимости совпавших признаков, наличия похожих других значимых объектов, значительного совпадения по какой-либо категории признаков.
Процесс извлечения знаний экспертами представлен на рис. 5.
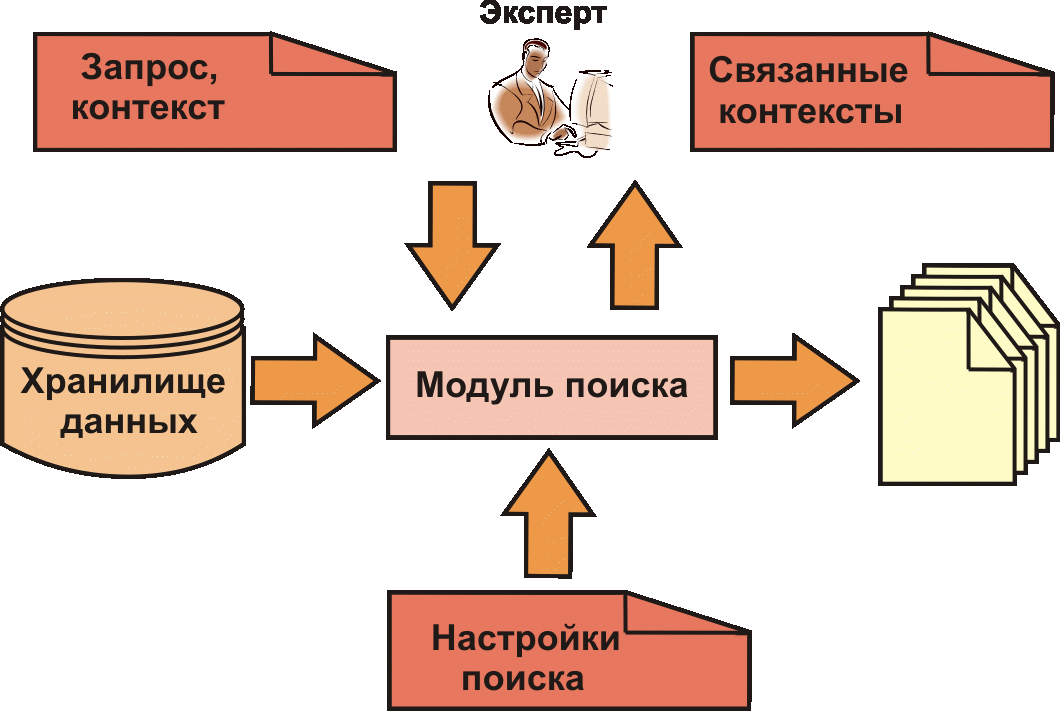
Увеличить guziy032009-05.gif (47кб)
Рис. 5. Извлечение знаний из хранилища данных
Мониторинг фактографической информации
Мониторинг фактографической информации может выполняться в различных контекстах, в зависимости от стоящих задач. В системе могут быть предусмотрены следующие возможности по мониторингу фактографической информации:
- автоматизированное ведение досье на объект;
- мониторинг ситуаций в соответствии с их типологиями.
Автоматизированное ведение досье на объект
Данный режим предполагает построение досье на некоторый информационный объект (как правило, лицо или организацию). Досье строится на основе имеющихся данных в базе фактографической информации на момент его построения. Для требуемых досье устанавливается режим мониторинга, при котором вся вновь поступающая фактографическая информация соотносится с существующим досье. Если выявляются связи, то новые объекты добавляются в досье автоматически.
Обычно для установленного на мониторинг досье выполняется также, в случае его пополнения, автоматическая проверка на соответствие стандартным типологиям.
Мониторинг ситуаций в соответствии с их типологиями
Для мониторинга стандартные типологии описываются формальным образом - выбираются типовые объекты и проставляются типовые связи между ними. Для установленных на мониторинг типологий, поступающая фактографическая информация проверяется на соответствие типологии, и, в случае выявления ситуации, выполняется сигнальное оповещение пользователя.
Как правило, данная методика используется для проверки построенных досье на соответствие стандартным типологиям.
Процесс мониторинга фактической информации представлен на рис. 6.
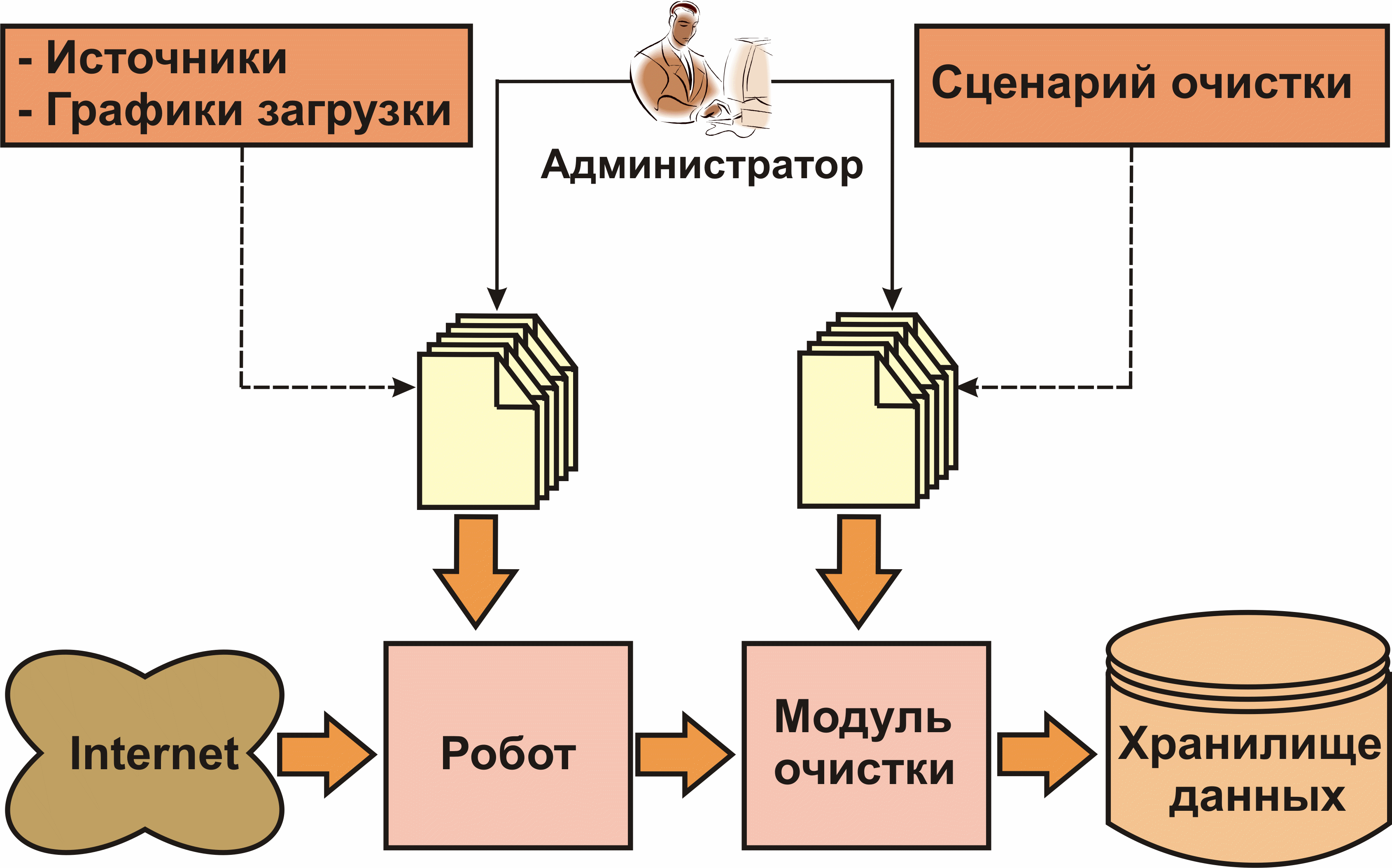
Увеличить guziy032009-06.gif (318кб)
Рис. 6. Мониторинг фактографической информации
Созданная на таких принципах информационная система объединяет, анализирует и хранит как единое целое информацию, извлекаемую как из учетных баз данных организации (компании, ведомства), так и из внешних источников, что служит основой для внедрения и эффективного функционирования системы активного управления безопасностью полетов не только корпоративного или ведомственного, но и государственного уровня.
1. Руководство по управлению безопасностью полетов (РУБП) (Doc 9859-AN/460). Издание первое. 2006 год. ИКАО, 2006.
2. Гузий А. Г., Лушкин А. М. Методологический подход к формированию корпоративной стратегии управления безопасностью полетов. // Проблемы безопасности полетов. 2008. № 9. С. 3 - 9.
3. Гузий. А. Г., Лушкин А. М., Чуйко Т. А. Априорное оценивание вероятности авиационного события в системе управления безопасностью полетов авиакомпании. // Проблемы безопасности полетов. 2009. № 2.
4. Reinhand Menzel / ICAO safety database strengthened by introduction of new software // ICAO Journal, Vol. 59, No 3, 2003.
5. Ноздрин В. И. Некоторые проблемы гражданской авиации. // Проблемы безопасности полетов. 2005. № 1. С. 8 - 24.
6. Руководство по предотвращению авиационных происшествий. (Doc 9422-AN/923). Первое издание. 1984год. ИКАО, 1984.
7. Руководство по представлению данных об авиационных происшествиях/инцидентах (ADREP) (Doc 9156). 2-е издание. ИКАО, 1987.
8. Приложение 13 к Конвенции о международной гражданской авиации. Расследование авиационных происшествий. ИКАО, 2001.
9. Глобальный план обеспечения безопасности полетов. ИКАО, июнь 2007.
10. Руководство по информационному обеспечению автоматизированной системы обеспечения безопасности полетов воздушных судов гражданской авиации Российской Федерации (АСОБП). М.: ООО «Аэронавигационное консалтинговое агентство», 2002.
11. Правила расследования авиационных происшествий и инцидентов с гражданскими воздушными судами в Российской Федерации. М.: АВИАИЗДАТ, 1998.
12. Государственная программа обеспечения безопасности полетов воздушных судов гражданской авиации РФ. Утверждена распоряжением Правительства РФ от 6 мая 2008 г. № 641-р.
13. David Vine. Internet Business Intelligence: How to Build a Big Company System on a Small Company Budget.
14. Щеглов И. Н., Чуйков Д. С., Печатнов Ю. А. Принципы построения естественно – языкового интерфейса перспективной АСУ ВВС. // Материалы 6-ой Всероссийской научно - технической конференции: «Повышение эффективности методов и средств обработки информации». Тамбов, 2000.
15. Jessica Keyes. Knowledge Management, Business Intelligence, and Content Management.
16. Щеглов И. Н., Богомолов А. В., Печатнов Ю. А. Исследование влияния репрезентативности обучающей выборки на качество работы методов распознавания образов. // Нейрокомпьютер: разработка и применение. 2002. №№ 9, 10.
Scientific bases of necessity and forming requirements to automation information flight safety system
A. G. Guziy (TRANSAERO Airlines),
I. N. Scheglov, M. A. Nikitov (VVIA of N. E. Zhukovsky)
Problems of information supply of procedures that estimate and manage flight safety level were marked. Necessity of automation of aviation transport system state on all levels and stages data acquisition, storage, presentation and use was proved. Requirements to automation information flight safety system (AIFSS) and its basic characteristics were formed. Description of fundamental technological processes of perspective AIFSS’s base and extended functionals was listed.
Keywords: automation information flight safety system.